Par Khaoula BENYAHYA, Data Analyst
En tant que Data Analyst Power BI, nous sommes souvent confrontés à des problèmes de performances. Il est alors recommandé de prendre en considération cette composante lors des développement et maintenance de nos rapports.
Cet article détaille, dans un premier temps, une liste d’outils permettant d’identifier la cause de la latence. Puis, il décrit les bonnes pratiques à adopter lors des phases de développement et d’optimisation d’un rapport.
- Pourquoi un rapport est lent ?
Le diagramme suivant aide à orienter le développeur lors de l’évaluation des causes de la latence constatée :
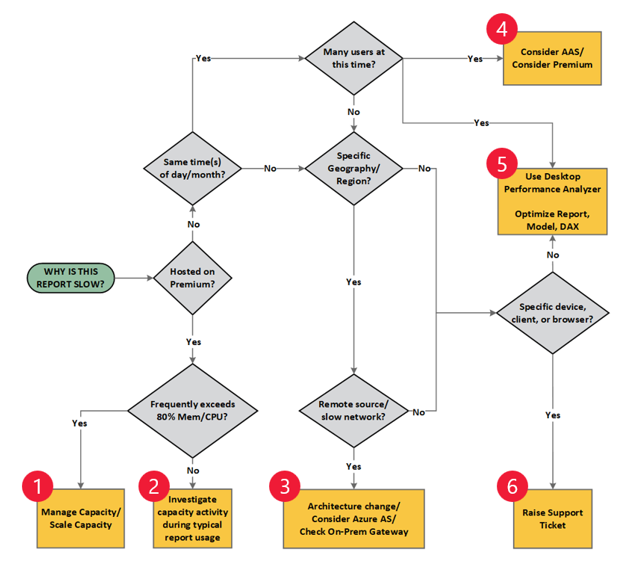
Source : https://docs.microsoft.com/fr-fr/power-bi/guidance/report-performance-troubleshoot
Dans le cas où l’arbre de décision nous redirige vers la mesure 5 (optimisation du rapport), nous devons réaliser une étude de l’existant afin d’identifier les axes d’amélioration possibles. Pour ce faire, nous disposons de différents outils, détaillés ci-dessous.
- Outils pour mesurer la performance des rapports Power BI :
Les outils suivants constituent une liste non exhaustive des solutions permettant l’analyse des performances de rapports Power BI :
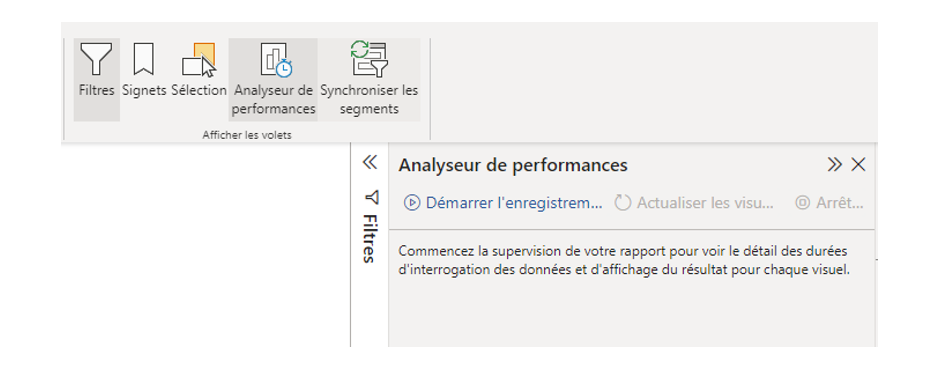
- Analyseur de performance – Power BI Desktop : mesure le temps d’exécution (en millisecondes) associé aux différentes actions effectuées sur le rapport. Il sert donc à mesurer quels sont les traitements les plus couteux en temps d’exécution afin de connaître les visuels et traitements à optimiser en priorité.
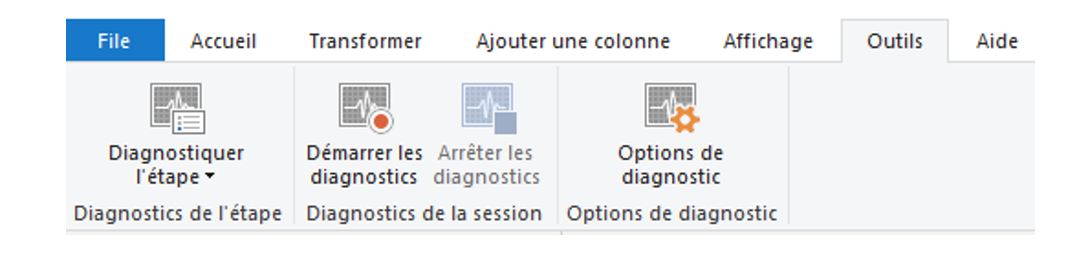
- Diagnostic de requêtes Power Query :
Pour comprendre le type de requêtes émises et les ralentissements qui peuvent avoir lieu lors de l’actualisation du modèle, ainsi que le type d’évènements qui se produisent en arrière-plan :
- Dax Studio :
Pour mesurer la performance d’une requête DAX :
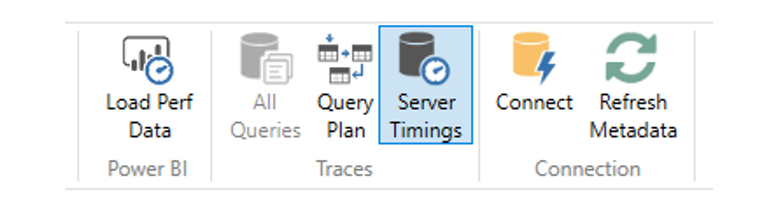
Pour mesurer la taille des tables et quelle colonne occupe le plus d’espace en mémoire :
Lorsque les rapports sont hébergés sur une capacité Premium, il est également possible d’identifier les rapports lents en surveillant l’application Power BI Premium Metrics.
- Bonnes pratiques pour améliorer la performance des rapports :
Voici les bonnes pratiques à mettre en place pour améliorer la performance des rapports Power BI. La performance peut être améliorée sur 5 niveaux :
- Connectivité et choix du mode de stockage ;
- Passerelle ;
- Modèle de données ;
- Requêtes DAX ;
- Design
1- Connectivité et mode de stockage :
Le choix du mode de connectivité dépend de plusieurs facteurs :
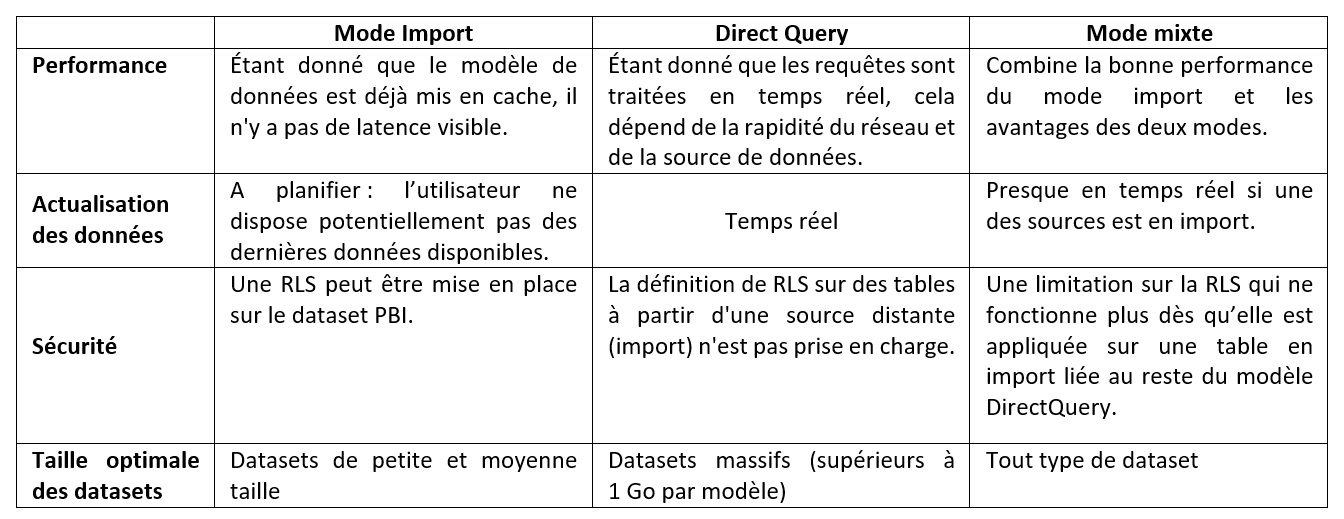
En résumé, le mode Import offre de meilleures performances mais requiert davantage de mémoire dans le service Power BI ainsi qu’une gestion spécifique de l’actualisation des données.
A contrario, le mode DirectQuery n’est pas soumis à ces contraintes par son mécanisme d’interrogation en temps réel de la source de données connexe. Cependant, cela entraine une augmentation de la latence puisque toutes les requêtes s’exécutent à la volée.
Le mode Mixte permet de trouver un équilibre entre les performances des rapports, les données en temps réel, la taille et le temps d’actualisation du dataset.
2. Passerelle :
La passerelle est mise en place quand on interroge une source de données locale. Elle agit comme un pont entre la source de données et le service Power BI. Voici des bonnes pratiques à appliquer lors du déploiement de passerelles :
- Placer le serveur de passerelle aussi proche que possible des sources de données pour minimiser la latence du réseau. Si le serveur de passerelle est loin de la source, les informations devront passer par plusieurs ordinateurs et composants d’infrastructure. Chaque étape ajoute une petite quantité de délai de traitement, qui peut augmenter lorsque les réseaux sont encombrés.
- Supprimer la limitation du réseau : certains pare-feu ou proxy réseau peuvent être configurés pour limiter les connexions afin d’optimiser la connectivité Internet. Cela peut ralentir les transferts via la passerelle.
- Éviter d’exécuter d’autres applications ou services sur la passerelle, surtout sur les environnements de production. Cela garantit que les charges provenant d’autres applications ne peuvent pas avoir d’impact imprévisible sur les requêtes.
- Séparer les passerelles des sources de données DirectQuery des sources de données en import (qui demandent une actualisation planifiée) autant que possible. Cela permet d’éviter la mise en file d’attente de milliers de requêtes DirectQuery dans la passerelle au moment de l’actualisation planifiée d’un modèle de données volumineux.
- Utiliser un stockage local suffisant et rapide : le serveur de passerelle met en Buffer (mémoire tampon) les données avant de les envoyer dans le cloud. En cas d’actualisation de plusieurs datasets volumineux en parallèle, il faut s’assurer d’avoir assez d’espace en mémoire pour pouvoir les stocker temporairement en local. Il est donc recommandé d’utiliser des options de stockage à haut débit et faible latence (par exemple les disques SSD) pour éviter que le stockage ne devienne un goulot d’étranglement.
- Favoriser la passerelle de données locale (on-premise) au lieu de la passerelle personnelle (Personal Gateway). La Personal Gateway importe des données dans Power BI. La passerelle on-premise (également appelée Enterprise Gateway) n’importe rien, ce qui est plus efficace en cas de grands volumes de données.
3. Modèle de données :
Pour améliorer la performance au niveau du modèle de données :
- Favoriser le modèle en étoile au lieu d’un modèle en flocon.
- Favoriser la création de nouveaux champs (colonnes) directement sur la source de données plutôt que de créer des colonnes calculées. Une colonne est recalculée à chaque actualisation du rapport ce qui fait perdre la performance.
- Privilégier la création de mesures des colonnes. Une colonne est physiquement stockée dans le fichier, elle augmente donc la taille du dataset et le temps d’actualisation. Contrairement à une mesure qui permettra de réduire le temps d’actualisation ainsi que la taille du fichier .pbix.
- Supprimer les tables ou les colonnes non utiles pour diminuer la taille du dataset et avoir un modèle simple. Cela améliorera aussi l’expérience utilisateur.
- Renommer les champs directement sur la source de données si possible, pour éviter les étapes de « rename» dans le modèle de données. Ce sont des étapes de transformation supplémentaires que le modèle n’aura pas à exécuter.
- Favoriser le filtrage simple (à sens unique) et ne pas activer les relations du filtrage croisé bidirectionnel sauf dans un contexte d’utilisation et intérêt bien définis. L’activation de cette option peut entraîner des ambiguïtés, un suréchantillonnage, des résultats inattendus et une détérioration potentielle des performances. L’ambiguïté associée à ce type de filtrage est amplifiée dans une relation plusieurs-à-plusieurs en raison de la multitude de chemins entre les différentes tables.
- Activer la sécurité au niveau des lignes (RLS : Row Level Security) pour restreindre l’accès des utilisateurs à certaines lignes d’une base de données en fonction du rôle exécutant une requête. Avec la RLS, Power BI importe uniquement les données que l’utilisateur est autorisé à afficher.
- Éviter d’utiliser des types de données à virgule flottante (Float) car ils peuvent entraîner des erreurs d’arrondi imprévisibles et réduire les performances des rapports.
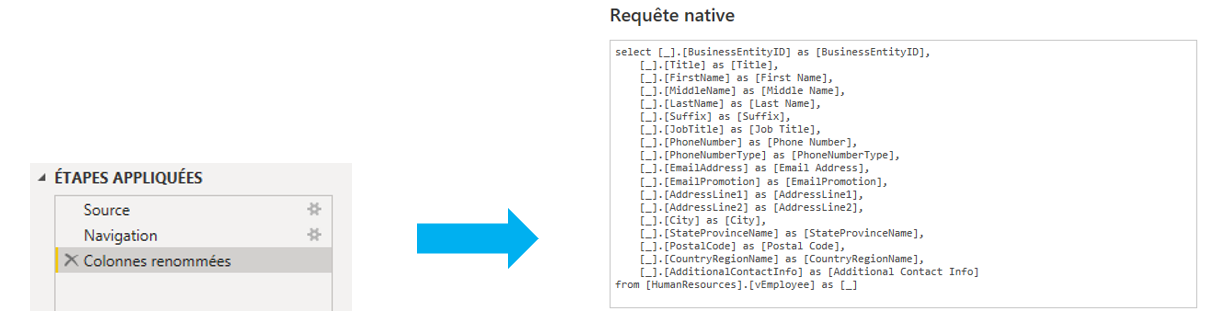
- Appliquer le « Query Folding» : cela signifie que le moteur Power Query peut traduire les étapes de transformations en une seule requête qui est envoyée à la source de données dans son langage de requête natif :
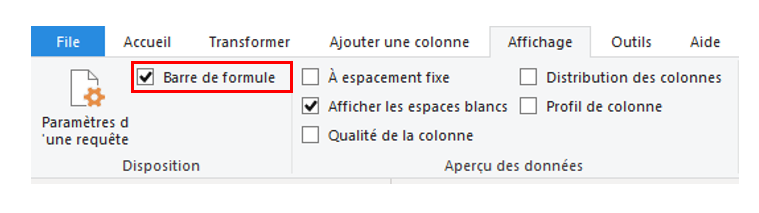
Pour cela, sur l’éditeur de requêtes Power Query, vérifier que la « barre de formule » est activée sur l’onglet « Affichage » :
4. Requêtes DAX :
Pour améliorer la performance des mesures et des requêtes DAX créées :
- Se méfier des fonctions qui nécessitent d’évaluer chaque ligne d’une table (par exemple SUMX). Ce type de fonctions parcourt l’ensemble de la table, ligne par ligne : calcule une expression pour chaque ligne d’une table spécifiée, stocke temporairement le résultat de chaque ligne, additionne tous ces résultats puis libère la mémoire temporaire et renvoie le résultat final. Il faut donc les utiliser uniquement si nécessaire car elles consomment plus.
- Utiliser des variables au lieu de répéter les définitions de mesures pour ne pas dupliquer les mêmes calculs dans une seule mesure. Par exemple, la mesure basique pour calculer un taux d’évolution des ventes par rapport à N-1 est la suivante :
YoY% = DIVIDE (
SUM ( [Total Sales] )
– CALCULATE ( SUM ( [Total Sales] ), DATEADD ( ‘Calendrier'[Date], –1, YEAR ) ),
CALCULATE ( SUM ( [Total Sales] ), DATEADD ( ‘Calendrier'[Date], –1, YEAR ) ) )
La valeur des ventes N-1 est référencée deux fois et peut être stockée dans une variable.
Une façon plus optimisée de calculer ce taux est donc la suivante :
YoY%_VAR =
VAR __PREV_YEAR = CALCULATE ( SUM ( [Total Sales] ), DATEADD ( ‘Calendrier'[Date], –1, YEAR ) )
RETURN
DIVIDE ( ( SUM ( [Total Sales] ) – __PREV_YEAR ), __PREV_YEAR )
- Éviter d’utiliser FILTER dans les fonctions qui acceptent les conditions de filtre : les fonctions telles que CALCULATE et CALCULATETABLE acceptent un paramètre de filtre utilisé pour ajuster le contexte du calcul. La fonction FILTER renvoie une table, ce qui n’est pas efficace lorsqu’elle est utilisée comme condition de filtre dans d’autres fonctions.
La mesure suivante permet de calculer les ventes effectuées sur la catégorie « Accessories » :
Sales = CALCULATE ( [Sales], FILTER ( ‘Product’, ‘Product'[Category] == « Accessories » ) )
Il est préférable de remplacer l’expression de table par une expression booléenne, comme suit :
Sales = CALCULATE ( [Sales], ‘Product'[Category] == « Accessories » )
- Utiliser SUMMARIZE uniquement pour les colonnes de texte : Bien que cette fonction autorise n’importe quel type de colonne, il est conseillé de ne pas utiliser de colonnes numériques pour des raisons de performances. Il faut utiliser plutôt SUMMARIZECOLUMNS, qui est plus récent et plus optimisé. La raison en est que SUMMARIZECOLUMNS fonctionne dans un contexte de ligne, alors que la même expression dans un SUMMARIZE est exécutée dans un contexte de filtre correspondant aux valeurs des colonnes groupées.
- Utiliser ISBLANK au lieu de = BLANK pour vérifier les valeurs vides : ils obtiennent le même résultat, mais ISBLANK est plus rapide.
- Utiliser IFERROR et ISERROR de manière appropriée : Ils peuvent être enroulés autour d’une mesure pour fournir des alternatives en cas d’erreurs de calcul. Cependant, ils doivent être utilisés avec précaution car ils augmentent le nombre d’analyses requises au niveau du moteur de stockage et peuvent forcer les opérations ligne par ligne dans le moteur. Il est recommandé de traiter les erreurs de données à la source ou dans les étapes ETL pour éviter d’effectuer une vérification des erreurs en DAX.
- Utiliser la fonction DIVIDE au lieu de l’opérateur de division : En divisant des nombres, il faut gérer les valeurs vides ou nulles dans le dénominateur pour éviter les erreurs. L’intérêt de la fonction DIVIDE est qu’elle gère automatiquement ces cas au niveau du moteur de stockage ce qui est plus rapide. De plus, elle a un troisième paramètre facultatif qui permet de spécifier une valeur alternative à utiliser si le dénominateur est nul ou vide.
La mesure suivante permet de calculer le profit :
Profit = IF ( OR ( ISBLANK ( [Sales] ), [Sales] == 0 ), BLANK (), [Profit] / [Sales] )
Une version améliorée utiliserait la fonction DIVIDE, comme suit :
Profit = DIVIDE ( [Profit], [Sales] )
- Utiliser COUNTROWS plutôt que COUNT : la fonction COUNT compte les valeurs de colonne et COUNTROWS compte les lignes de la table. Les deux fonctions renvoient le même résultat, dans la mesure où la colonne comptée (avec COUNT) ne contient pas de valeurs BLANK. Pour éviter tout type d’erreur, il est meilleur d’utiliser COUNTROWS car elle est plus efficace et donc plus performante. De plus, elle ne tient pas compte des valeurs BLANK contenues dans les colonnes de la table.
5. Design :
L’amélioration des performances d’un rapport passe également par la conception et l’agencement des différents visuels :
- Limiter le nombre de visuels par page. Chaque page doit contenir de 5 à 7 visuels au maximum.
- Limiter l’interaction entre les visuels si elle n’est pas nécessaire. Cela réduira le nombre de requêtes exécutées car une sélection dans un visuel n’affecte plus tous les autres.
- Utiliser des arrière-plans de rapport pour les images statiques plutôt que plusieurs visuels.
- Utiliser des signets, des pages d’accès au détail et des info-bulles. Ceux-ci permettent de réduire le volume et la complexité des requêtes exécutées et donc de réduire le temps de chargement de la page.
- Tester les performances des visuels personnalisés car ceux-ci peuvent mal fonctionner lors de la gestion de grands ensembles de données ou d’agrégations complexes. Les visuels personnalisés non certifiés ne sont généralement pas testés par l’équipe Power BI et sont donc déconseillés.
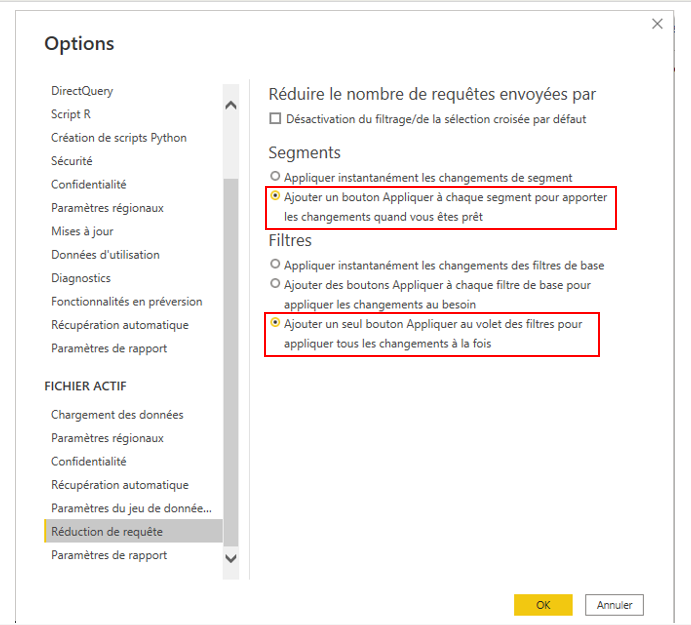
- Réduire le nombre de requêtes envoyées par Power BI à l’aide des paramètres de réduction des requêtes. Pour les slicers, sélectionner l’option « Ajouter un bouton Appliquer à chaque slicer pour appliquer les changements quand vous êtes prêt ».
Pour les filtres, sélectionner « Ajouter un seul bouton Appliquer au volet de filtres pour appliquer les changements à la fois « .
- Combiner des cartes individuelles dans des cartes à plusieurs lignes ou des tableaux : Une pratique de rapport courante consiste à utiliser de nombreux visuels de cartes individuelles pour afficher des métriques récapitulatives dans une ligne. Or, chacun de ces visuels émettra une requête.

Lorsque les mesures proviennent du même visuel, les moteurs de stockage de données peuvent souvent récupérer des données et calculer plusieurs mesures en un seul lot. Par conséquent, en utilisant une seule carte multi-lignes ou un visuel de tableau, une seule requête sera émise.
En conclusion, il est possible d’améliorer les performances d’un rapport à chaque étape de son développement, de la collecte des données sources à la conception des visuels. A travers cet article, nous avons détaillé les bonnes pratiques à adopter et appliquer afin d’obtenir un rapport Power BI performant. Celles-ci se basent au préalable sur une bonne compréhension des causes potentielles de latence obtenue à l’aide des outils décrits en introduction.