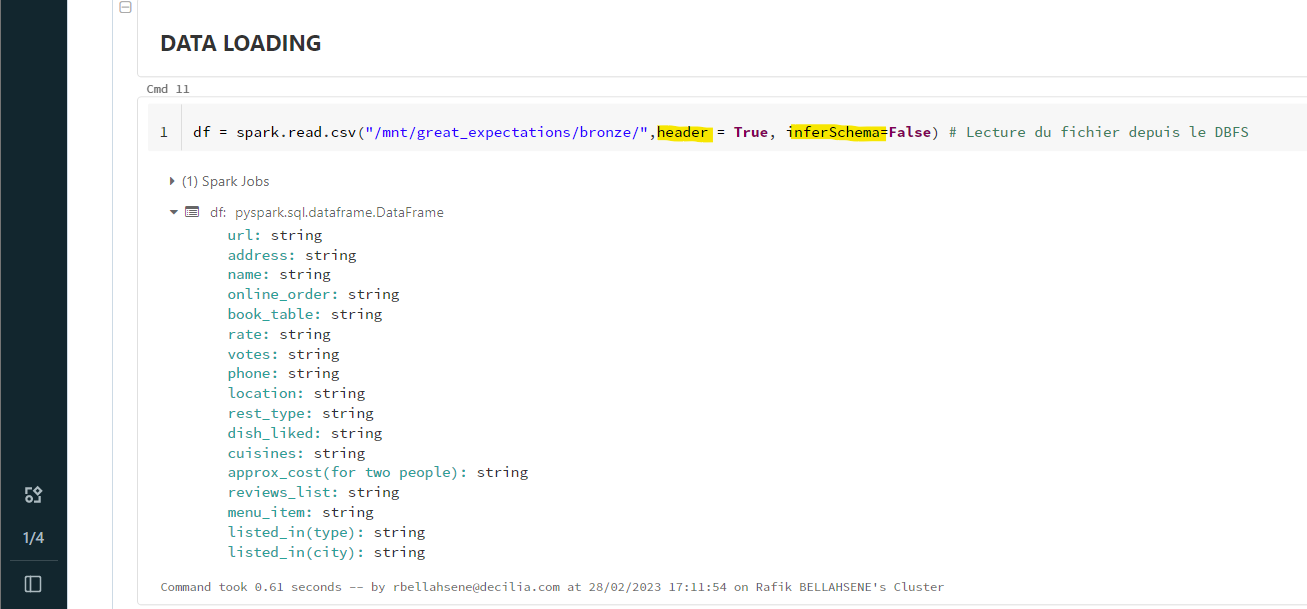
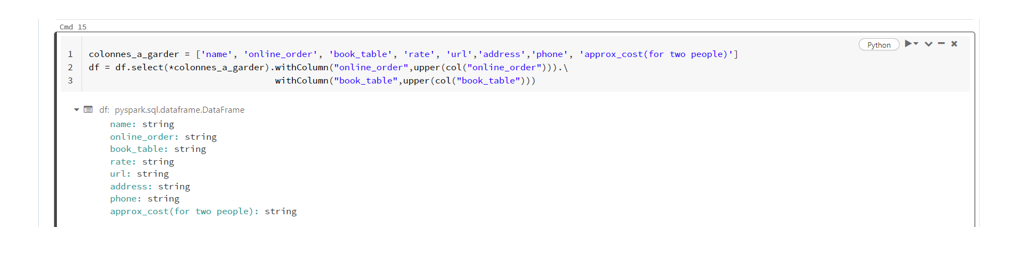
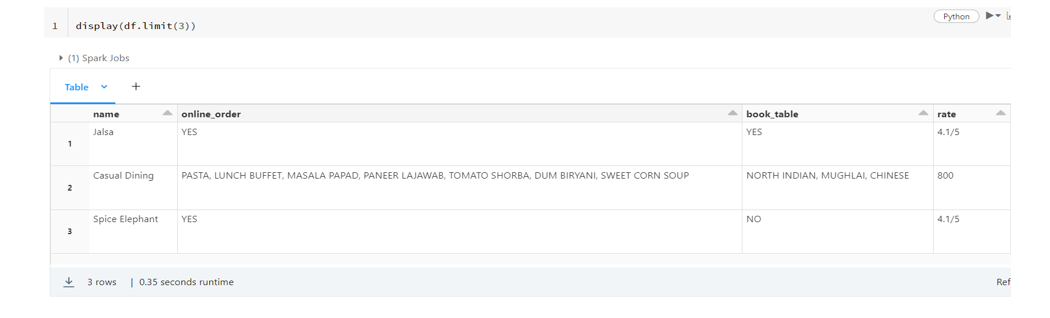
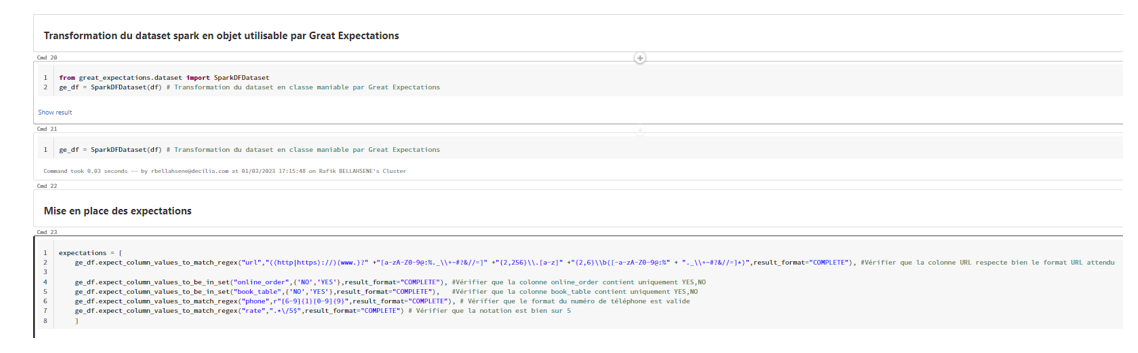
When you visit our website, it may store information through your browser from specific services, usually in form of cookies. Here you can change your privacy preferences. Please note that blocking some types of cookies may impact your experience on our website and the services we offer.
Privacy Policy
You have read and agreed to our privacy policy